![]()
![]()
![]()
![]()
![]()
![]()
Check out the full ARETE documentation for more information
What is ARETE?
ARETE (Antimicrobial Resistance: Emergence, Transmission, and Ecology) is a bioinformatics best-practice analysis pipeline for profiling the genomic repertoire and evolutionary dynamics of microorganisms with a particular focus on pathogens. We use ARETE to identify important genes (e.g., those that confer antimicrobial resistance or contribute to virulence) and mobile genetic elements such as plasmids and genomic islands, and infer important routes by which these are transmitted using evidence from recombination, cosegregation, coevolution, and phylogenetic trees comparisons.
ARETE produces a range of useful outputs (see outputs), including those generated by each tool integrated into the pipeline, as well as summaries across the entire dataset such as phylogenetic profiles. Outputs from ARETE can also be easily fed into packages such as Coeus and MicroReact for further analyses. Although ARETE was primarily developed with pathogens in mind, inference of pan-genomes, mobilomes, and phylogenomic histories can be performed for any set of microbial genomes, with the proviso that reference databases are much more complete for some taxonomic groups than others. In general, the tools in ARETE work best at the species and genus level of relatedness.
A key design feature of ARETE is the versatility to find the right blend of software packages and parameter settings that best handle datasets of different sizes, introducing heuristics and swapping out tools as necessary. ARETE has been benchmarked on datasets from fewer than ten to over 10,000 genomes from a diversity of species and genera including Enterococcus faecium, Escherichia coli, Listeria, and Salmonella. Another key feature is enabling the user choice to run specific subsets of the pipeline; a user may already have assembled genomes, or they may not care about, say, recombination detection. There are also cases where it might be necessary to manually review the outputs from a particular step before moving on to the next one; ARETE makes this manual QC easy to do.
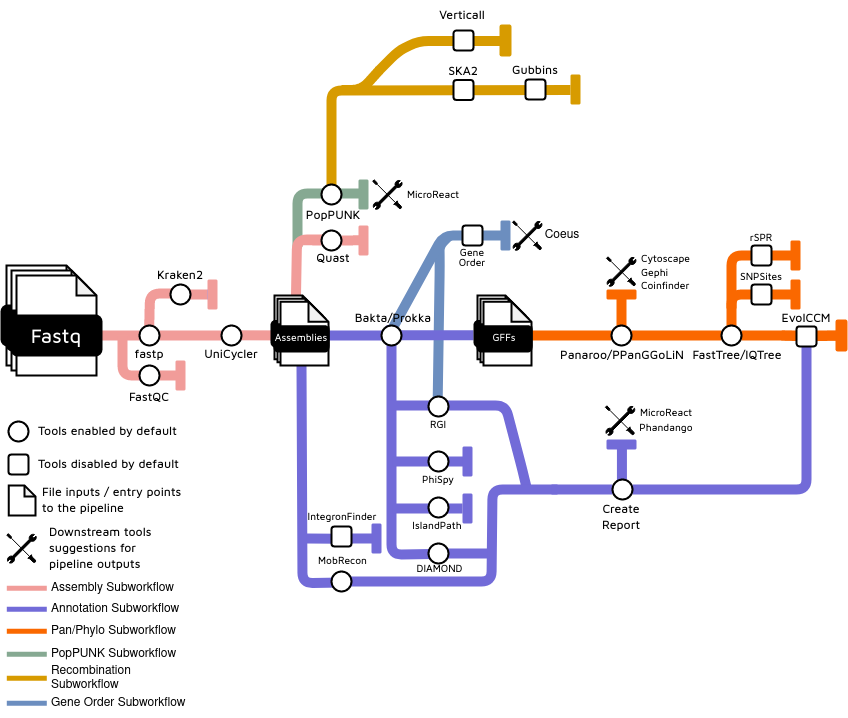
Table of Contents
About the pipeline
The pipeline is built using Nextflow, a workflow tool to run tasks across multiple compute infrastructures in a very portable manner. It uses Docker / Singularity containers making installation trivial and results highly reproducible.
Like other workflow languages it provides useful features like -resume to only rerun tasks that haven't already been completed (e.g., allowing editing of inputs/tasks and recovery from crashes without a full re-run).
The nf-core project provided overall project template, pre-written software modules when available, and general best-practice recommendations.
ARETE is organized as a series of subworkflows, each of which executes a different conceptual step of the pipeline. The subworkflow organization provides suitable entry and exit points for users who want to run only a portion of the full pipeline.
Genome subsetting
The user can optionally subdivide their set of genomes into related lineages identified by PopPUNK (See documentation). PopPUNK quickly assignes genomes to 'lineages' based on core and accessory genome identity. If this option is selected, all genomes will still be annotated, but cross-genome comparisons (e.g., pan-genome inference and phylogenomics) will use only a single representative genome from each lineage. The user can run PopPUNK with a spread of different thresholds and decide how to proceed based on the number of lineages produced and their own specific knowledge of the genetic population structure of the taxon being analyzed.
Short-read processing and assembly
- Raw Read QC (
FastQC) - Read Trimming (
fastp) - Trimmed Read QC (
FastQC) - Taxonomic Profiling (
kraken2) - Unicycler (
unicycler) - QUAST QC (
quast) - CheckM QC (
checkm)
Annotation
- Genome annotation with Bakta (
bakta) or Prokka (prokka) -
Feature prediction:
-
AMR genes with the Resistance Gene Identifier (
RGI) - Plasmids with MOB-Suite (
mob_suite) - Genomic Islands with IslandPath (
IslandPath) - Phages with PhiSpy (
PhiSpy) - (optionally) Integrons with
IntegronFinder - Specialized databases: CAZY, VFDB, BacMet and ICEberg2 using DIAMOND homology search (
diamond)
Phylogenomics
- (optionally) Genome subsetting with PopPUNK (See documentation)
- Pan-genome inference using PPanGGOLiN (
PPanGGOLiN) or Panaroo (panaroo) - Reference and gene tree inference using FastTree (
fasttree) or IQTree (iqtree) - (optionally) SNP-sites (
SNPsites)
Recombination detection (optionally)
- Recombination detection is performed within lineages identified by PopPUNK (
poppunk). Note that this application of PopPUNK is different from the subsetting described above. - Genome alignment using SKA2 (
ska2) - Recombination detection using Verticall (
verticall) and/or Gubbins (gubbins)
Coevolution
- (optionally) Identification of coordinated gain and loss of features using EvolCCM (
EvolCCM)
Lateral gene transfer
- (optionally) Phylogenetic inference of LGT using rSPR (
rSPR)
Gene order
- (optionally) Comparison of genomic neighbourhoods using the Gene Order Workflow (
Gene Order Workflow)
See our roadmap for a full list of future development targets.
Quick Start
-
Install
nextflow -
Install
DockerorSingularity. Also ensure you have a workingcurlinstalled (should be present on almost all systems).2.1. Note: this workflow should also support
Podman,ShifterorCharliecloudexecution for full pipeline reproducibility. Configuremailon your system to send an email on workflow success/failure (without this you may get a small error at the endFailed to invoke workflow.onComplete event handlerbut this doesn't mean the workflow didn't finish successfully). -
Download the pipeline and test with a
stub-run. Thestub-runwill ensure that the pipeline is able to download and use containers as well as execute in the proper logic.nextflow run beiko-lab/ARETE -profile test,<docker/singularity> -stub-run3.1. Please check nf-core/configs to see if a custom config file to run nf-core pipelines already exists for your Institute. If so, you can simply use
-profile <institute>in your command. This will enable eitherdockerorsingularityand set the appropriate execution settings for your local compute environment.3.2. If you are using
singularitythen the pipeline will auto-detect this and attempt to download the Singularity images directly as opposed to performing a conversion from Docker images. If you are persistently observing issues downloading Singularity images directly due to timeout or network issues then please use the--singularity_pull_docker_containerparameter to pull and convert the Docker image instead. In case of input datasets larger than 100 samples, check our resource profiles documentation, for optimal usage. -
Start running your own analysis (ideally using
-profile dockeror-profile singularityfor stability)!
nextflow run beiko-lab/ARETE \
-profile <docker/singularity> \
--input_sample_table samplesheet.csv \
--poppunk_model bgmm
samplesheet.csv must be formatted sample,fastq_1,fastq_2, with the first column being sample names and the other two corresponding to compressed FASTQ files.
Note: If you get this error at the end Failed to invoke `workflow.onComplete` event handler it isn't a problem, it just means you don't have an sendmail configured and it can't send an email report saying it finished correctly i.e., its not that the workflow failed.
See usage docs for all of the available options when running the pipeline. See the parameter docs for a list of all parameters currently implemented in the pipeline and which ones are required. See the FAQ for a list of frequently asked questions and common issues.
Testing
To test the worklow on a minimal dataset you can use the test configuration (with either docker or singularity - replace docker below as appropriate):
nextflow run beiko-lab/ARETE -profile test,docker
To accelerate it you can download/cache the database files to a folder (e.g., test/db_cache) and provide a database cache parameter.
nextflow run beiko-lab/ARETE \
-profile test,docker \
--db_cache $PWD/test/db_cache \
--bakta_db $PWD/baktadb/db-light
We also provide a larger test dataset, under -profile test_full, for use in ARETE's annotation entry. This dataset is comprised of 8 bacterial genomes. As a note, this can take upwards of 20 minutes to complete on an average personal computer.
Replace docker below as appropriate.
nextflow run beiko-lab/ARETE -entry annotation -profile test_full,docker
Examples
The fine details of how to run ARETE are described in the command reference and documentation, but here are a couple of illustrative examples of how runs can be adjusted to accommodate genome sets of different sizes:
Assembly, annotation, and pan-genome inference from a modestly sized dataset (50 or so genomes) from paired-end reads
nextflow run beiko-lab/ARETE \
--input_sample_table samplesheet.csv \
--annotation_tools 'mobsuite,rgi,vfdb,bacmet,islandpath,phispy,report' \
--poppunk_model bgmm \
-profile docker
Parameters used:
--input_sample_table- Input dataset in samplesheet format (See usage)--annotation_tools- Select the annotation tools and modules to be executed (See the parameter documentation for defaults)--poppunk_model- Model to be used by PopPUNK-profile docker- Run tools in docker containers.
Annotation to evolutionary dynamics on 300-ish genomes
nextflow run beiko-lab/ARETE \
--input_sample_table samplesheet.csv \
--poppunk_model dbscan \
--run_recombination \
--run_gubbins \
-entry annotation \
-profile medium,docker
Parameters used:
--input_sample_table- Input dataset in samplesheet format (See usage)--poppunk_model- Model to be used by PopPUNK.--run_recombination- Run the recombination subworkflow.--run_gubbins- Run Gubbins as part of the recombination subworkflow.--use_ppanggolin- Use PPanGGOLiN for calculating the pangenome. Tends to perform better on larger input sets.-entry annotation- Run annotation subworkflow and further steps (See usage).-profile medium,docker- Run tools in docker containers. For-profile medium, check our resource requirements documentation.
Annotation to evolutionary dynamics on 10,000 genomes
nextflow run beiko-lab/ARETE \
--input_sample_table samplesheet.csv \
--poppunk_model dbscan \
--run_recombination \
-entry annotation \
-profile large,docker
Parameters used:
--input_sample_table- Input dataset in samplesheet format (See usage)--poppunk_model- Model to be used by PopPUNK.--run_recombination- Run the recombination subworkflow.--use_ppanggolin- Use PPanGGOLiN for calculating the pangenome. Tends to perform better on larger input sets.--enable_subsetting- Enable subsetting workflow based on genome similarity (See subsetting documentation)-entry annotation- Run annotation subworkflow and further steps (See usage).-profile large,docker- Run tools in docker containers. For-profile large, check our resource requirements documentation.
Annotation on a tiny dataset (4-12 genomes) in a personal computer
While ARETE is primarily designed to run in HPC clusters, we have implemented a simple, bare-bones version that is able to run on most modern computers and laptops, with at most 6 CPU cores and a minimum of 8GB of memory.
Keep in mind this will make it impossible to run most tools included in ARETE, but it should still provide a useful testing ground.
nextflow run beiko-lab/ARETE \
--input_sample_table samplesheet.csv \
--poppunk_model bgmm \
-entry annotation \
-profile light,docker
- Note the addition of the
lightprofile, this is the configuration for running on personal computers. - Check out how to assign resource requests for even more customization.
Run all ARETE subworkflows in a small dataset
The command below will run all tools included in the annotation subworkflow and will enable the recombination, gene order, rSPR and evolCCM subworkflows.
Be aware that the performance of the evolCCM and Gene Order subworkflows with large or very diverse datasets can be subpar.
nextflow run beiko-lab/ARETE \
--input_sample_table samplesheet.csv \
--annotation_tools 'mobsuite,rgi,cazy,vfdb,iceberg,bacmet,islandpath,phispy,integronfinder,report' \
--run_recombination \
--run_evolccm \
--run_rspr \
--run_gene_order \
--poppunk_model dbscan \
-profile docker
Credits
The ARETE software was originally written and developed by Finlay Maguire and Alex Manuele, and is currently developed by João Cavalcante.
Rob Beiko is the PI of the ARETE project. The project Co-PI is Fiona Brinkman. Other project leads include Andrew MacArthur, Cedric Chauve, Chris Whidden, Gary van Domselaar, John Nash, Rahat Zaheer, and Tim McAllister.
Many students, postdocs, developers, and staff scientists have made invaluable contributions to the design and application of ARETE and its components, including Haley Sanderson, Kristen Gray, Julia Lewandowski, Chaoyue Liu, Kartik Kakadiya, Bryan Alcock, Amos Raphenya, Amjad Khan, Ryan Fink, Aniket Mane, Chandana Navanekere Rudrappa, Kyrylo Bessonov, James Robertson, Jee In Kim, and Nolan Woods.
ARETE development has been supported from many sources, including Genome Canada, ResearchNS, Genome Atlantic, Genome British Columbia, The Canadian Institutes for Health Research, The Natural Sciences and Engineering Research Council of Canada, and Dalhousie University's Faculty of Computer Science. We have received tremendous support from federal agencies, most notably the Public Health Agency of Canada and Agriculture / Agri-Food Canada.
Contributing to ARETE
If you would like to contribute to ARETE, please see the contributing guidelines.
Citing ARETE
Please cite the tools used in your ARETE run: A comprehensive list can be found in the CITATIONS.md file.
An early version of ARETE was used for assembly and feature prediction in the following paper:
Sanderson H, Gray KL, Manuele A, Maguire F, Khan A, Liu C, Navanekere Rudrappa C, Nash JHE, Robertson J, Bessonov K, Oloni M, Alcock BP, Raphenya AR, McAllister TA, Peacock SJ, Raven KE, Gouliouris T, McArthur AG, Brinkman FSL, Fink RC, Zaheer R, Beiko RG. Exploring the mobilome and resistome of Enterococcus faecium in a One Health context across two continents. Microb Genom. 2022 Sep;8(9):mgen000880. doi: 10.1099/mgen.0.000880. PMID: 36129737; PMCID: PMC9676038.
This pipeline uses code and infrastructure developed and maintained by the nf-core initative, and reused here under the MIT license.
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.